
The Premier League is one of the most popular football tournaments in the world, attracting not only fans but also bettors. European odds are simple and easy to understand, based on three outcomes: win, draw, lose. However, predicting the results of matches is not always easy due to the high competition and surprises in football bet. To increase the chances of winning, players need to apply scientific analysis methods. One of the powerful tools is the decision tree analysis model. This article will explore how to use the decision tree model to optimize European odds for Premier League matches.
1. Understanding the decision tree model
The decision tree model is a data analysis tool that allows identifying and evaluating factors affecting the outcome of a dependent variable. The structure of this model is like a tree, with the root being the main decision and the branches being the choices based on specific conditions. The final outcome is determined at the leaves of the tree, representing predictions or classifications. In football, decision trees can help players identify important factors such as team form, player strength, or playing conditions to predict the outcome of the match.
2. Why is the decision tree suitable for European handicaps?
European handicaps only have three possible outcomes: win, draw, lose. This makes the decision tree an ideal tool because it has the ability to classify clearly and easily. Moreover, the decision tree can visualize the decision-making process, making it easy for players to monitor and adjust their betting strategies. The ability to analyze multiple variables and find hidden rules in the data is also a strength of the decision tree, helping to optimize the choice of European handicaps.
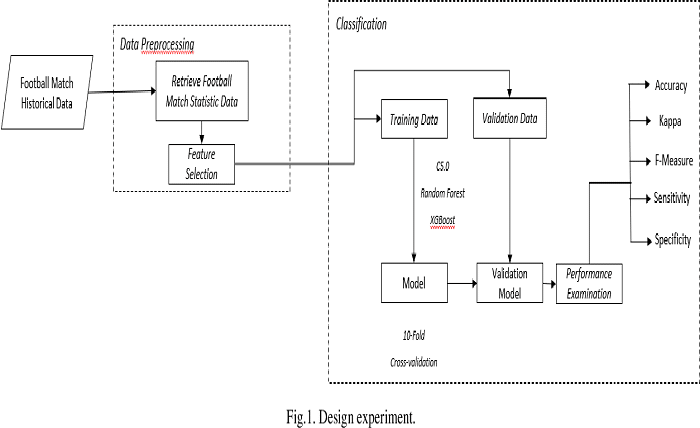
3. Prepare the data for the model
To build an effective decision tree for the Premier League European handicap, it is necessary to collect and process the data carefully. The data should include match results, team information, home/away performance, goal statistics, and external factors such as weather and tight match schedules. After collecting, the data needs to be cleaned to remove noise and normalize the values to ensure consistency when entering the model.
4. Build and deploy the decision tree
Once the data is ready, the next step is to build a decision tree model. The decision tree model will analyze the data and identify important decision points, from which it will build a tree with branches and leaves representing betting decisions. The final result will be predictions of match results based on the analyzed factors.
5.Evaluate and improve the model
After the decision tree model is built, performance evaluation is a necessary step to ensure accuracy and efficiency. Players can compare the model’s predictions with the actual results of the matches to determine the level of accuracy. If necessary, the model can be adjusted by adding or removing variables, or changing the tree structure. This evaluation and improvement process should be done continuously to maintain the performance of the model.
6. Apply the model results to betting
Once the decision tree model has been optimized, players can use the results of the model to make European betting decisions. For example, if the model shows a high probability for a match to end with a home team victory, players can bet on this team’s victory. On the contrary, if the model indicates a high probability of a draw, the player can consider betting on a draw. Using a decision tree model helps players rely on data and scientific analysis instead of emotions, thereby optimizing the chance of winning.
Betting experience shows that mathematical models can often be applied very well to betting.



